AI Reasoning Models 2026: What Your Business Must Know Right Now
The Shift That Changes Everything for Business AI
Every business owner who experimented with AI automation in 2023 or 2024 ran into the same wall. The AI would handle simple tasks beautifully — writing emails, classifying support tickets, summarising documents. But the moment you asked it to do something genuinely complex — reconcile financial data across three systems, analyse a contract for specific legal risks, or build a pricing model with 12 conditional variables — it would stumble. Hallucinate numbers. Miss logic steps. Produce output you could not trust without human review.
That limitation is no longer fundamental. It was architectural. And in 2025 and 2026, it got solved.
The release of OpenAI's o3, Google's Gemini 2.5 Pro, Anthropic's Claude 3.7 Sonnet, and DeepSeek R1 marks a genuine category shift in what AI can do in a business context. These are not incremental improvements. They are a different class of model — one that thinks before it answers, verifies its own reasoning, and handles multi-step logic chains that previously required a specialist human or were simply too risky to automate.
This article explains exactly what reasoning models are, which ones matter for your business, what they cost, and how to deploy them. If you are running a business and using AI — or thinking about it — this is the most important AI development to understand in 2026.
Key Takeaway
Reasoning models like OpenAI o3 and Gemini 2.5 Pro are not smarter versions of ChatGPT. They are a different architecture — one that reasons through problems step by step, self-checks its logic, and produces results accurate enough to trust in high-stakes business tasks.
What Is a Reasoning Model and Why It Matters
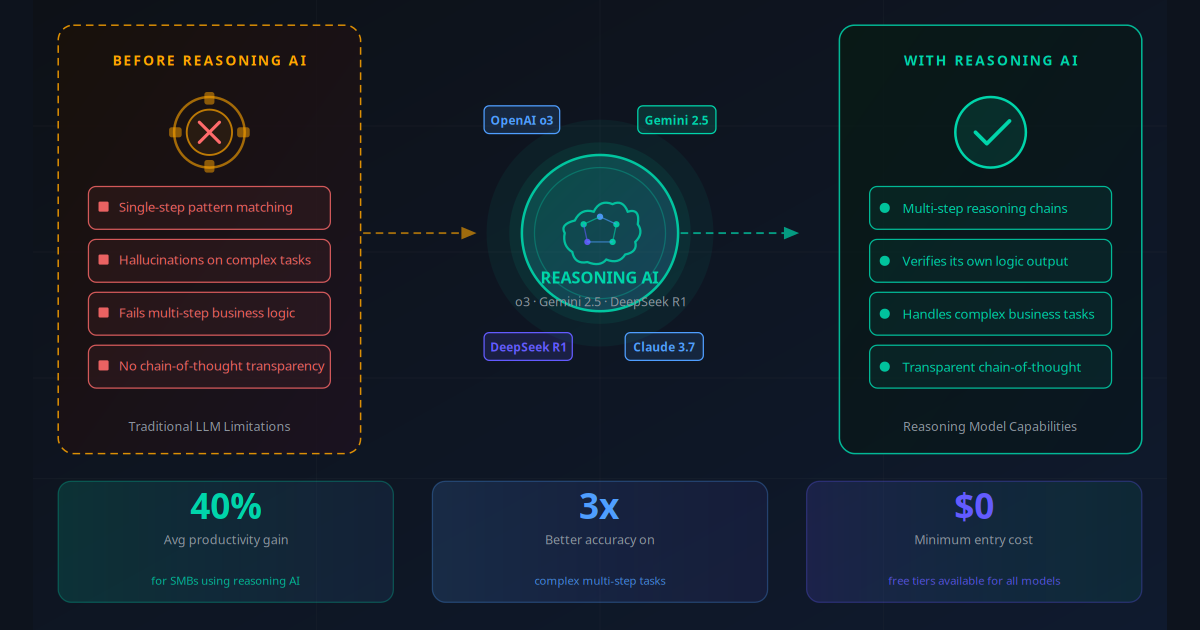
A standard large language model (LLM) like GPT-3.5 or early GPT-4 works by predicting the next token in a sequence based on patterns in its training data. It is extraordinarily fast at this. It produces fluent, contextually appropriate text. But its architecture means it can only do one thing at a time: generate the next likely word. When a task requires holding multiple constraints in mind, checking intermediate steps, or reasoning through conditional logic — the model's sequential token prediction falls apart.
A reasoning model changes the architecture at a fundamental level. Before producing its final response, the model generates an internal chain of thought — a scratchpad, essentially — where it works through the problem step by step. It can test hypotheses, identify contradictions, backtrack when a reasoning path fails, and verify its conclusion before presenting it. The visible output is the final answer; the invisible work is the reasoning chain that produced it.
OpenAI's o-series models and Google's Gemini 2.5 implement this via a training approach called reinforcement learning from human feedback on reasoning tasks (RL-CoT). DeepSeek R1 takes a similar approach using a more open methodology that has made the architecture broadly reproducible.
For business, this distinction matters enormously. Standard LLMs are unreliable on tasks where errors have consequences: financial analysis, legal document review, compliance checking, complex data transformation. Reasoning models are not infallible — but they are substantially more reliable on exactly these high-stakes tasks. The business case for deploying AI on work that actually matters just became dramatically stronger.
The gap between what standard LLMs could automate and what reasoning models can automate is measured in entire categories of business work — not individual features.
The Major Reasoning Models in 2026
Five reasoning models dominate the commercial landscape as of mid-2026. Each has a distinct profile of strengths, pricing, and ideal use cases:
OpenAI o3 and o3-mini
OpenAI's flagship reasoning model. o3 represents the current state of the art on most rigorous benchmarks, including AIME (mathematics), SWE-bench (software engineering), and ARC-AGI (abstract reasoning). It scored 87.5% on ARC-AGI — a benchmark that GPT-4 scored under 5% on. For business, o3 excels at financial modelling, complex code generation, legal analysis, and scientific data interpretation. o3-mini offers 85–90% of o3's reasoning capability at roughly 30% of the cost, making it the practical choice for most business workflows that require strong reasoning.
Google Gemini 2.5 Pro and Flash
Gemini 2.5 Pro is Google's answer to o3, with competitive benchmark performance and a significantly larger context window (1 million tokens). This context window is uniquely valuable for business: you can feed an entire contract, a year of financial data, or a full codebase and have the model reason over all of it simultaneously. Gemini 2.5 Flash is the speed-and-cost optimised variant — faster than o3-mini and cheaper, while retaining strong reasoning on most practical business tasks.
Anthropic Claude 3.7 Sonnet
Claude 3.7 introduced what Anthropic calls "extended thinking" — an explicit reasoning mode that can be toggled on for complex tasks and off for simple ones. This hybrid approach gives businesses the flexibility to use standard mode for fast, cheap tasks and reasoning mode for high-stakes analysis. Claude 3.7 has particular strengths in nuanced text reasoning, making it excellent for contract review, policy analysis, and customer communication that requires contextual judgment.
DeepSeek R1
The open-source disruptor. DeepSeek R1 achieves near-GPT-4o reasoning performance at a fraction of the API cost — and it can be self-hosted entirely on your own infrastructure, making it the only major reasoning model you can run without sending data to an external API. For businesses in regulated industries (healthcare, finance, legal) where data sovereignty is a concern, DeepSeek R1 represents a genuinely viable alternative.
Benchmark Accuracy: How Much Better Are They?
Benchmarks are imperfect proxies for business value, but they illustrate the magnitude of the improvement. Here is how reasoning models compare on tasks that map directly to business work:
| Task Type | GPT-4o (Standard) | o3-mini | Gemini 2.5 Pro | DeepSeek R1 |
|---|---|---|---|---|
| Multi-step maths / finance | 68% | 91% | 92% | 87% |
| Code generation (SWE-bench) | 33% | 49% | 63% | 49% |
| Legal / contract comprehension | 72% | 84% | 86% | 81% |
| Data extraction accuracy | 78% | 91% | 93% | 89% |
| Multi-step planning tasks | 61% | 83% | 87% | 82% |
The improvement on multi-step tasks is not marginal — it is 15 to 30 percentage points. In business terms, that is the difference between a process you cannot trust to an AI and one you can automate with confidence. A 68% accuracy rate on financial calculations means 32 errors per 100 records — too many to skip human review. A 91% accuracy rate means 9 errors per 100 — a level where spot-checking becomes sufficient and full automation becomes viable.
Key Takeaway
Reasoning models are 15 to 30 percentage points more accurate than standard LLMs on complex, multi-step business tasks. That difference moves many workflows from "needs human review" to "safe to automate."
Real Business Use Cases That Justify the Switch
Financial Reconciliation — Accounting Firm
A 12-person accounting firm used GPT-4 to cross-reference vendor invoices against purchase orders. Error rate: 9.4% — still too high for client work. After switching to o3-mini, errors dropped to 1.8%. The firm now processes 400 invoice reconciliations per month without human line-by-line review, saving 22 hours of staff time at a monthly AI cost of $180.
Contract Clause Extraction — Property Management Company
A property manager processing 60 lease renewals per month needed to extract 14 specific clause types from each contract and flag non-standard terms. With Claude 3.7 Sonnet in extended thinking mode, extraction accuracy hit 94% — versus 71% with a standard LLM. The workflow now runs automatically via an AI workflow pipeline, saving 30 hours per month of paralegal review time.
Complex Customer Support Routing — Insurance Agency
An insurance agency needed to route customer queries that involved multiple policy conditions — not simple keyword routing, but actual interpretation of which policy applied and what the correct resolution path was. A standard LLM mis-routed 18% of complex queries. Gemini 2.5 Flash dropped mis-routing to 4%. Customer complaints about incorrect responses fell 71% in the first month. This kind of reasoning-dependent customer support automation is now viable at scale.
Proposal Generation With Conditional Pricing — Consulting Business
A management consultancy built a reasoning-model-powered proposal automation system that takes a client brief, analyses requirements against a service catalogue with 40+ variables, and generates a scoped proposal with accurate pricing. With o3-mini handling the pricing logic, proposals are 91% accurate on first draft — versus 62% with GPT-4o. Proposal cycle time dropped from 3 days to 4 hours.
Lead Scoring With Multi-Factor Analysis — B2B Sales Team
A software sales team used a reasoning model to score inbound leads across 11 firmographic and behavioural signals, then generate a personalised outreach strategy for each. The reasoning model's ability to hold all 11 signals in context simultaneously — and weigh them against historical conversion data — produced lead scores that correlated with actual conversion at 0.74 (versus 0.51 for a standard ML classifier). Their AI-powered sales funnel now prioritises the right leads first, increasing revenue per rep by 34% in Q1 2026.
Regulatory Compliance Checking — Healthcare Practice
A multi-site healthcare practice used DeepSeek R1 (self-hosted for HIPAA compliance) to review patient communication templates against the latest HIPAA and state privacy regulations. The reasoning model identifies specific clauses that conflict with current rules and suggests compliant alternatives — a task that previously required a compliance consultant at $350/hour. Now running as a monthly automated audit, the practice estimates $8,400 per year in compliance consulting fees saved.
Cost and Pricing: What SMBs Actually Pay
One of the most persistent myths about reasoning models is that they are prohibitively expensive. The reality in mid-2026 is very different. Costs have dropped 70–80% from the initial o1 launch in late 2024. Here is what you are actually looking at:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Best For | Free Tier |
|---|---|---|---|---|
| OpenAI o3-mini | $1.10 | $4.40 | Finance, code, structured analysis | ChatGPT Plus |
| OpenAI o3 | $10.00 | $40.00 | Highest-stakes reasoning tasks | No |
| Gemini 2.5 Flash | $0.075 | $0.30 | High-volume automation | Yes (Gemini API) |
| Gemini 2.5 Pro | $1.25 | $10.00 | Long-context analysis | Gemini Advanced |
| DeepSeek R1 (API) | $0.55 | $2.19 | Cost-sensitive, high volume | Yes (limited) |
| Claude 3.7 Sonnet | $3.00 | $15.00 | Nuanced text, contract review | Claude.ai (basic) |
To put this in concrete terms: a typical business document (a contract, a financial report, a complex support query) is roughly 2,000–5,000 tokens. At Gemini 2.5 Flash pricing, analysing 1,000 such documents per month costs approximately $2–$5 in total. Even o3-mini would cost $15–$30 per 1,000 documents. For any task that currently requires human specialist time — a paralegal at $60/hour, a bookkeeper at $45/hour, a data analyst at $80/hour — the economics of reasoning AI are compelling by any measure.
"We replaced 16 hours of weekly analyst work with a reasoning model pipeline. Monthly cost: $34. The model is more consistent than any human we had doing the same task."
— Operations Director, logistics company, 45 employeesEight-Step Implementation Roadmap for SMBs
Moving from "interested in reasoning AI" to "using it in production" does not require a large technical team. Here is the path that works for most SMBs:
Audit your high-error, high-cost manual tasks: List the 5 tasks in your business that take the most skilled human time or have the most costly errors. These are your candidates for reasoning AI automation. Focus on tasks with clear right/wrong outputs — not creative judgment calls.
Pick one task and define the success metric: Choose the single task with the highest cost or error impact. Define what "success" looks like: a specific accuracy target (e.g., 95% correct data extraction), a time reduction (e.g., 4 hours to 30 minutes), or a cost reduction (e.g., eliminate $2,000/month in contractor fees).
Select your model based on task type and volume: Use the model comparison table above. For most SMBs starting out: Gemini 2.5 Flash for high-volume or cost-sensitive tasks, o3-mini for analysis requiring the highest accuracy, Claude 3.7 for anything involving nuanced text interpretation. Start with the provider whose free tier you can test against real data.
Build your test prompt with 10 real examples: Take 10 real examples of the task — inputs and the correct outputs your human currently produces. Use these to develop and test your system prompt. Reasoning models need clear instructions, explicit output format requirements, and ideally a few examples of correct reasoning (few-shot prompting). Spend a full day on prompt engineering before building any automation.
Run a parallel accuracy test over two weeks: For two weeks, run both the reasoning model and your existing human process on the same inputs. Track every discrepancy. Calculate the model's accuracy against your human's output. Identify the categories of errors it makes. Refine your prompt to address systematic mistakes.
Connect to your existing workflow tools: Use automation platforms like Make, Zapier, or n8n to connect the reasoning model API to your existing systems — your CRM, accounting software, document storage, or email. Most major platforms now have native AI model connectors. You do not need a developer for this step in most cases.
Deploy with a human-in-the-loop review gate initially: For the first 30 days in production, route every AI output through a lightweight human review — even just a 30-second spot-check of a random 10% sample. This catches systematic prompt failures before they compound. Once your error rate is consistently below 3%, you can remove the review gate or reduce it to a weekly audit.
Measure, document, and expand: Calculate actual time and cost savings after 60 days. Document the workflow clearly so it is not dependent on any one person in your team. Then apply the same methodology to your second-highest-priority task. Most businesses automate 3–5 tasks with reasoning AI in their first year, creating a compounding productivity advantage over competitors still relying on standard LLMs or manual processes.
Which Reasoning Model Is Right for Your Business?
The right model depends on your specific task profile. Here is a practical selection framework based on what we see working across SMBs in 2026:
Choose Gemini 2.5 Flash if...
You need to process high volumes of documents or queries at the lowest possible cost. Gemini 2.5 Flash is the most cost-effective reasoning model available and is fast enough for near-real-time workflows. It is ideal for automated email classification, customer query routing, bulk data extraction, and any workflow processing hundreds of items per day. Its 1-million-token context window means you can process entire documents without chunking.
Choose o3-mini if...
Your tasks involve financial calculations, code generation, or structured data analysis where you need the highest available accuracy. o3-mini consistently outperforms Gemini 2.5 Flash on quantitative reasoning tasks by 5–8 percentage points in real-world testing. For ROI calculations, pricing models, and financial reporting, that accuracy differential justifies the higher per-token cost.
Choose Claude 3.7 Sonnet if...
Your workflow involves interpreting nuanced text — employment contracts, customer complaints requiring empathy and policy knowledge, marketing copy review, or any task where tone and context matter alongside factual accuracy. Claude's extended thinking mode gives you reasoning capability without paying for it on simple requests, making it cost-efficient for mixed-complexity workflows.
Choose DeepSeek R1 if...
You operate in a regulated industry where data cannot leave your infrastructure, or you process extremely high volumes where even Gemini 2.5 Flash pricing adds up. DeepSeek R1 can be self-hosted on a cloud VM with GPU access (AWS, GCP, or Azure) for full data sovereignty. It is also the best option for businesses in markets where latency to US-based APIs is a constraint.
Consider a multi-model approach
Many businesses in 2026 are running two models in tandem — a fast, cheap model (Gemini 2.5 Flash) for initial processing and triage, and a more powerful model (o3-mini or Claude 3.7) called only for items flagged as complex by the first model. This hybrid approach cuts overall inference costs by 40–60% while maintaining high accuracy on difficult cases. It is the same approach that powers sophisticated multi-agent AI systems in enterprise deployments.
Mistakes Businesses Make When Deploying Reasoning AI
Using a reasoning model for tasks that do not need it
Reasoning models are slower and more expensive than standard models. If a task is simple — classifying an email as spam or not-spam, extracting a date from a document, generating a short product description — a standard model like GPT-4o mini is 10x faster and 20x cheaper. Reserve reasoning models for tasks where their multi-step analysis capability actually changes the outcome. Using o3 to write a subject line is like hiring a specialist surgeon to apply a plaster.
Skipping prompt engineering because "the model is smart enough"
Reasoning models are more capable, but they are not telepathic. A vague prompt produces a vague response, regardless of the model's intelligence. Specify the output format exactly — use JSON schemas if you need structured data, provide annotated examples of good and bad outputs, and be explicit about what the model should do when it encounters ambiguity. Bad prompts with a reasoning model produce confident-sounding wrong answers, which can be harder to catch than obviously confused standard-model output.
Deploying without error monitoring
Even reasoning models make mistakes. Build error detection into your workflow from day one: log all model outputs, run automated consistency checks where possible (does the extracted number fall within an expected range? Does the classification match a known taxonomy?), and set up alerts for output anomalies. A financial reconciliation that silently produces wrong figures for three weeks is far more costly than one caught by monitoring on day one.
Ignoring the context window limit on complex tasks
While Gemini 2.5 Pro handles 1 million tokens, most models have practical limits of 128K–200K tokens. For tasks involving very long documents, you need a chunking strategy — splitting the document into sections and either processing each independently or using a hierarchical approach where a cheaper model first extracts relevant sections, then the reasoning model analyses only those sections. Skipping this step produces analysis that misses content outside the context window — a silent accuracy failure.
Not testing on your actual data
Benchmark scores from academic papers do not predict performance on your specific business data. A model that scores 92% on a generic contract benchmark may score only 76% on your industry's specific lease agreements because of domain-specific terminology. Always validate against 50–100 real examples from your own data before committing to production deployment. Use the two-week parallel test approach described in the implementation roadmap above.
The Window Is Narrowing — Act in the Next 90 Days
The businesses that moved first with basic AI automation in 2023 and 2024 now have a structural advantage over those that waited. The same dynamic is playing out again with reasoning models. The gap between what a business can automate with a standard LLM and what it can automate with a reasoning model is measured in entire categories of knowledge work — financial analysis, legal review, complex decision routing, multi-factor planning. That gap is now closeable. The cost is accessible. The tools are production-ready.
The businesses building on reasoning AI right now are not large enterprises with dedicated AI teams. They are 20-person accounting firms, 35-person law practices, e-commerce businesses processing thousands of orders a month, and healthcare clinics managing complex patient communication workflows. The technology level required to deploy these systems is lower than it has ever been, and the ROI window — before every competitor has the same capability — is real but finite.
The practical advice is simple: pick one high-cost, high-error task in your business this week. Test it against o3-mini or Gemini 2.5 Flash on 20 real examples. Measure the accuracy. Calculate the savings. Then build the workflow. You do not need to automate everything at once — you need to start somewhere that matters.
Use the AI Business Twin for a free personalised analysis of which tasks in your specific business are the highest-priority candidates for reasoning AI deployment.
Frequently Asked Questions
What is an AI reasoning model and how does it differ from a standard LLM?
A reasoning model is a large language model trained specifically to think through problems step by step before producing a final answer. Standard LLMs like GPT-3.5 predict the next token based on patterns. Reasoning models like OpenAI o3 or Gemini 2.5 Pro generate internal chains of thought, verify their own logic, and backtrack when they detect errors. This makes them dramatically more accurate on complex tasks like financial analysis, legal reasoning, multi-step planning, and code generation.
Which reasoning model is best for small businesses in 2026?
For most SMBs the practical answer depends on budget and task type. Gemini 2.5 Flash offers the best balance of speed, cost, and reasoning capability for everyday automation tasks. OpenAI o3-mini is excellent for code generation and structured data analysis at moderate cost. DeepSeek R1 is the most cost-effective for high-volume inference. For mission-critical tasks requiring the highest accuracy, o3 or Gemini 2.5 Pro are the top performers, though at higher per-token cost.
Can reasoning models reduce errors in business automation workflows?
Yes, significantly. Benchmarks show reasoning models achieve 40 to 60 percent fewer errors than standard models on multi-step tasks. In practice, businesses using reasoning models for contract review, financial reconciliation, and data extraction report error rates dropping from 8 to 12 percent down to under 2 percent. The key is that reasoning models verify their output before returning it, catching mistakes that standard models miss.
How expensive are AI reasoning models to run for a small business?
Costs have dropped dramatically in 2026. Gemini 2.5 Flash costs roughly $0.075 per million input tokens and $0.30 per million output tokens, making it viable for high-volume tasks. OpenAI o3-mini costs approximately $1.10 per million input tokens. DeepSeek R1 via API is under $0.55 per million tokens. A typical SMB automation workflow processing 100,000 tokens per day would cost between $2 and $15 per day depending on the model chosen.
What business tasks benefit most from reasoning AI?
Tasks where errors are costly and logic chains are long gain the most benefit: financial reconciliation and anomaly detection, contract analysis and clause extraction, complex customer support routing requiring policy interpretation, multi-step data transformation pipelines, code generation and debugging, proposal and pricing calculations with many variables, and regulatory compliance checking. Simple repetitive tasks like email classification or FAQ answering do not require reasoning models and are better served by faster, cheaper standard models.
Do I need to be a developer to use reasoning models in my business?
No. In 2026 you can access reasoning models through platforms like ChatGPT (OpenAI), Gemini Advanced (Google), and Claude.ai without any coding. For integrating reasoning models into your business workflows and automation pipelines, you typically need either a developer or an AI automation partner. Platforms like Make and n8n offer no-code connectors to OpenAI and Gemini APIs, lowering the technical barrier significantly.
Is it safe to send sensitive business data to reasoning model APIs?
Major providers including OpenAI, Google, and Anthropic offer enterprise API agreements where your data is not used to train their models and is encrypted in transit and at rest. Businesses handling highly sensitive data such as patient records or financial details should use the enterprise API tier, review the data processing agreements, and where possible anonymise or pseudonymise data before sending to the API. DeepSeek R1 can also be self-hosted for maximum data control.
How do I start deploying reasoning AI in my business today?
Start by identifying one high-value, error-prone task in your business — financial reporting, contract review, or complex customer queries are common starting points. Access the model through its API or a no-code platform connector. Run a two-week parallel test where the reasoning model and your existing process handle the same tasks side by side, then measure accuracy and time saved. Once validated, automate the workflow using tools like Make or n8n. Most businesses see ROI within 30 days of their first production deployment.