Small Language Models 2026: The SMB Case for Cheaper, Faster AI
The GPT-4 Bill That Never Stops Growing
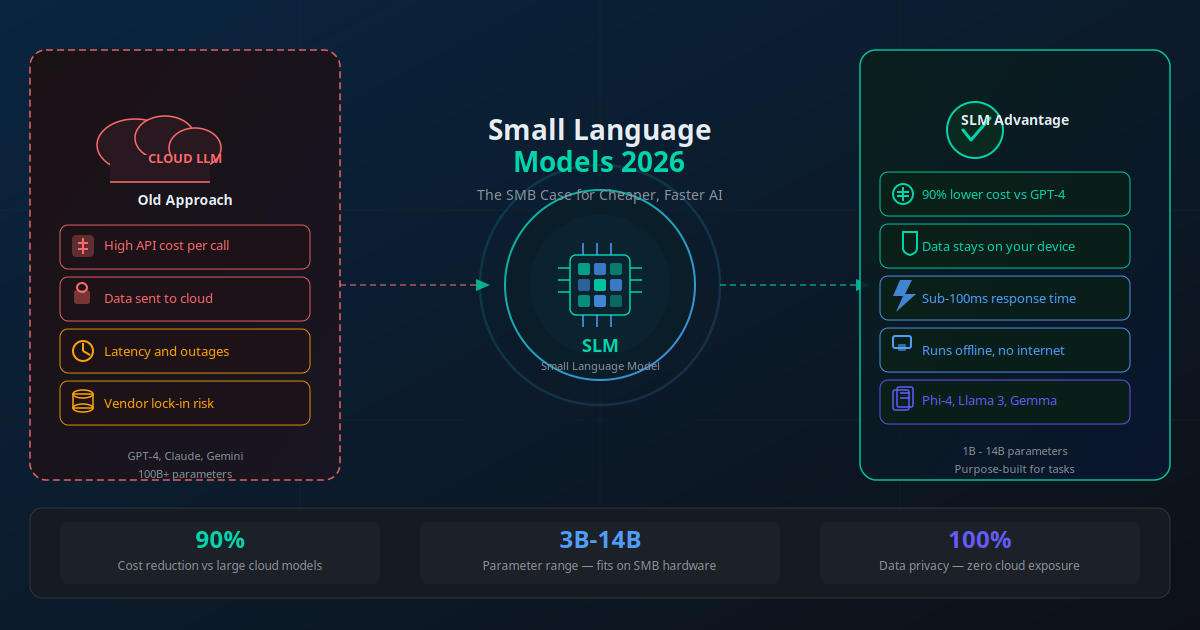
Your AI bill arrived and it was bigger than last month. Again. You are running customer support queries through GPT-4, summarising documents, classifying inbound emails, and generating templated replies. Every single token costs money — and at GPT-4 rates, a business processing 50,000 queries per month is easily spending $2,000–$5,000 on model inference alone. That is before you add the cost of your developer's time to maintain the integrations.
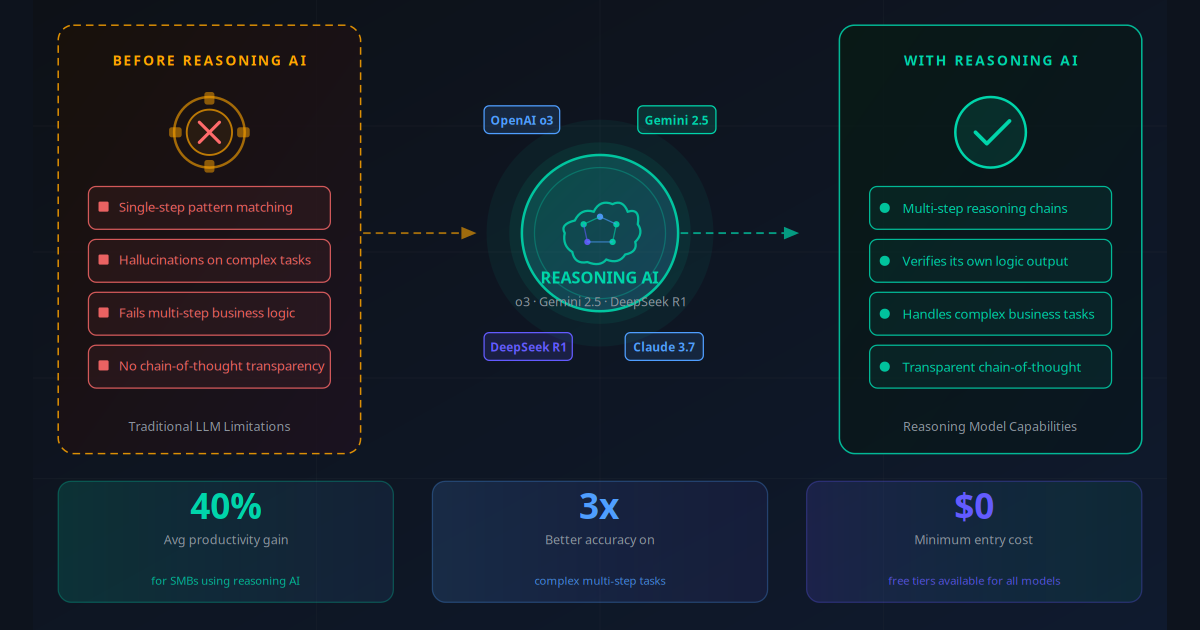
Now consider this: 80% of those queries are routine. FAQ answers, ticket categories, standard reply drafts. They do not require a 100-billion-parameter model trained on every book ever written. They need a focused, fast, well-tuned model that knows your business and its specific tasks. That is exactly what small language models deliver.
The SLM moment arrived in 2025 and is accelerating into 2026. Microsoft's Phi-4 benchmarks higher than GPT-3.5 on a range of reasoning tasks. Meta's Llama 3.1 8B runs on a standard laptop and handles customer service dialogue with remarkable quality. Google's Gemma 2 9B follows complex structured instructions more reliably than many larger models. And all of them cost a fraction of what you pay per API call to a cloud provider — or nothing at all when you self-host.
Key Takeaway
Small language models with 3–14 billion parameters now match large cloud models on most focused business tasks — at 90% lower cost and with full data privacy. For high-volume, repeatable AI workflows, SLMs have become the commercially superior choice in 2026.
What Is a Small Language Model?
A small language model (SLM) is a transformer-based AI model with a parameter count typically between 1 billion and 14 billion. For comparison, GPT-4 is estimated at 1.8 trillion parameters. The "small" in SLM is relative — even a 7-billion-parameter model is an extraordinarily capable system by any absolute measure. The key difference is in what they are designed to do.
Large models like GPT-4 and Claude 3 Opus are designed to be general-purpose. They can write poetry, debug code, explain quantum mechanics, and role-play fictional characters. That generality requires enormous scale. SLMs, by contrast, are designed for task-focused efficiency. They are typically:
- Fine-tuned on specific domains: A legal SLM knows legal language deeply; a customer service SLM knows dialogue patterns and resolution strategies.
- Instruction-optimised: Modern SLMs like Phi-4 and Gemma 2 are specifically trained to follow structured instructions reliably — making them ideal for business automation flows.
- Hardware-efficient: A 7B model runs on a $500 GPU. A 14B model fits on a single A10G cloud instance costing $0.75/hour — handling hundreds of concurrent queries.
- Deployable on-premise: You can run the entire model inside your own infrastructure. Your data never leaves your network.
The most important SLMs for business use in 2026 are Microsoft Phi-4 (14B), Meta Llama 3.1 8B and 70B, Google Gemma 2 (9B and 27B), Mistral 7B and Mixtral 8x7B, and Alibaba Qwen 2.5 (7B to 72B for multilingual tasks). All are freely available under permissive commercial licences.
SLM vs LLM: What the Numbers Actually Show
The benchmark results of 2025–2026 have surprised many observers. On focused business tasks, the performance gap between SLMs and large cloud models is much smaller than the parameter count would suggest — and on cost and speed, SLMs win decisively.
| Metric | GPT-4o (Cloud) | Phi-4 (14B, Self-Hosted) | Llama 3.1 8B (Self-Hosted) |
|---|---|---|---|
| Cost per 1M tokens | $5–$15 | ~$0.10 (hardware amortised) | ~$0.05 (hardware amortised) |
| Response latency (typical) | 800ms–2s | 80–200ms | 50–120ms |
| Data privacy | Sent to OpenAI servers | 100% on-premise | 100% on-premise |
| Customer FAQ accuracy | 94% | 91% | 87% |
| Ticket classification accuracy | 96% | 94% | 89% |
| Uptime dependency | OpenAI infrastructure | Your own server | Your own server |
| Hardware requirement | None (API) | 24 GB VRAM GPU | 16 GB VRAM GPU |
On general knowledge and creative tasks, GPT-4 remains ahead. But for the specific, repeatable queries that make up the bulk of business AI workloads, a well-tuned SLM delivers 90–96% of the accuracy at 3–5% of the cost. When you are processing 100,000 queries per month, that 3–5% cost point is the difference between AI being a strategic advantage and a financial burden.
"We replaced 80% of our GPT-4 API calls with a self-hosted Llama 3.1 8B. Our monthly AI infrastructure bill dropped from $3,400 to $280. Accuracy on our support routing task actually improved by 4% after fine-tuning on our own tickets."
Where SLMs Deliver the Highest ROI for SMBs
Customer Support: Ticket Classification and First-Response Drafts
A SaaS company processes 800 support tickets per day. Before SLMs, each ticket required a human to read, categorise, and draft an initial response — taking 4 minutes on average. After deploying a fine-tuned Llama 3.1 8B, the SLM classifies each ticket with 94% accuracy and drafts a first-response that the human agent reviews and sends in 45 seconds. Support capacity tripled without new hires. Monthly cost: $180 in cloud GPU time instead of $4,100 in GPT-4 API fees.
Legal and Finance: Document Review and Data Extraction
A law firm needed to extract key clauses from contracts — effective dates, termination conditions, liability caps — for due diligence reviews. Sending hundreds of client contracts to a third-party AI API violated their confidentiality obligations. A Phi-4 model deployed on the firm's own server handles the extraction with 93% accuracy, processes 200-page contracts in under 8 seconds, and keeps all data on-premise. Partner review time for routine contracts dropped by 67%.
E-commerce: Product Description Generation at Scale
An online retailer adding 500 new products per month was spending $1,800/month on copywriters for product descriptions. A Gemma 2 9B model fine-tuned on their brand voice and existing high-performing descriptions now generates first drafts for all 500 products, which a single part-time editor reviews. Copy production time dropped from 3 weeks to 3 days. Monthly cost fell from $1,800 to $210 — a saving of $19,080 per year.
Healthcare Administration: Patient Communication Drafting
A multi-location clinic needed to send personalised appointment reminders, post-visit follow-ups, and prescription renewal prompts to 2,000 patients per week. Using the cloud AI API meant patient data — names, diagnoses, appointment types — left the clinic's network. A HIPAA-compliant SLM deployment on the clinic's own server generates all patient communication locally. Operational staff time on patient outreach dropped by 14 hours per week across the group.
How to Deploy Your First SLM in 6 Steps
Getting a small language model running for a specific business task is faster than most business owners expect. Here is the practical path from zero to production:
Define one task to automate first: Pick a single high-volume, repeatable text task — ticket classification, FAQ answering, document summarisation, or email drafting. Avoid trying to build a general-purpose assistant. Focused tasks are where SLMs outperform large models on a cost-adjusted basis.
Choose your model: For customer-facing text generation, start with Llama 3.1 8B. For analytical and reasoning tasks, use Phi-4 14B. For structured instruction-following, try Gemma 2 9B. For multilingual tasks (Spanish, Arabic, Chinese), evaluate Qwen 2.5 7B. All are free to download from Hugging Face under commercial licences.
Set up serving infrastructure: For cloud hosting, an AWS g5.xlarge instance ($0.50/hour) with an NVIDIA A10G GPU handles Llama 3.1 8B at 60+ tokens per second. Use Ollama or vLLM as your model server — both expose an OpenAI-compatible API so your existing integrations need minimal changes. For on-premise, a single workstation with an RTX 4080 (16 GB VRAM) is sufficient for 8B models.
Fine-tune or prompt-engineer on your data: For most SMB use cases, prompt engineering alone gets you 85–90% of the way there — no model training required. Write a detailed system prompt that describes your business, the task, the output format, and 5–10 examples. For higher accuracy, fine-tune using LoRA (Low-Rank Adaptation) on 500–2,000 labelled examples from your own historical data. Fine-tuning takes 2–4 hours on a single GPU and produces dramatic accuracy gains.
Integrate with your existing tools: Connect the SLM API to your CRM, helpdesk, or workflow tool. Since most SLM serving frameworks expose an OpenAI-compatible API, existing integrations built for GPT-4 often work with a single URL and key change. Pair this with a workflow automation platform like Make or n8n to trigger the model on new tickets, form submissions, or document uploads.
Monitor, measure, and iterate: Log every query and response for the first 30 days. Set up a simple accuracy score — have team members rate outputs as correct/incorrect. Track your cost per query. Most teams see accuracy improve 5–10% in the first month simply from tightening the system prompt based on failure analysis. Once one use case is stable, apply the same playbook to the next high-volume task.
SLM Platforms and Serving Options in 2026
You have several options for serving SLMs, ranging from no-code cloud platforms to self-hosted open-source stacks. The right choice depends on your technical capability and data privacy requirements:
| Option | Data Privacy | Setup Effort | Cost (per month, 50K queries) | Best For |
|---|---|---|---|---|
| Ollama (self-hosted) | Full on-premise | Low (1 command install) | $0 + hardware | SMBs with a spare server or developer laptop |
| vLLM on AWS/GCP | Your cloud account | Medium (DevOps setup) | $80–$200 | High throughput production workloads |
| Groq Cloud API | Sent to Groq servers | None (API key) | $15–$60 | Ultra-low latency, non-sensitive data |
| Together AI API | Sent to Together servers | None (API key) | $10–$40 | Quick start, open model access |
| Azure AI (Phi-4) | Azure tenant (configurable) | Low (managed service) | $30–$80 | Microsoft ecosystem businesses |
For businesses with sensitive data — healthcare, legal, financial services — self-hosted Ollama or a private vLLM deployment is the clear choice. For businesses prioritising speed of deployment over privacy, Groq's API delivers the lowest latency of any hosted inference platform in 2026, processing Llama 3.1 8B at over 700 tokens per second. That is fast enough for real-time customer-facing applications like AI-powered support workflows and RAG-powered chatbots without the cost of a large cloud model.
The ROI Math: SLM vs Cloud API Over 12 Months
"We were spending $4,200 per month on OpenAI API costs for our customer support automation. After switching to a self-hosted Phi-4, our monthly AI cost is $340. That is a saving of $46,320 per year — and our data now stays in our own infrastructure."
— CTO, B2B software company, 45 employeesHere is a concrete ROI scenario for a mid-size retail business processing 80,000 AI queries per month across customer support, product descriptions, and email drafting:
- Cloud GPT-4o cost (input + output at average 800 tokens/query): ~$5,760/month
- Self-hosted Llama 3.1 8B (AWS g5.xlarge, 3 instances for redundancy): ~$1,080/month
- Monthly saving: $4,680
- Annual saving: $56,160
- One-time implementation cost (typical): $8,000–$15,000
- Payback period: 2–4 months
That is before accounting for the latency improvement (sub-100ms vs 1–2s responses) and the elimination of vendor dependency. Businesses using RAG-based AI assistants find the SLM migration even more compelling — the retrieval layer means the model does not need broad general knowledge, precisely the domain where SLMs are most competitive with large models.
For AI-driven lead generation workflows where an AI qualifies hundreds of inbound leads per day, the latency improvement alone has measurable conversion impact. A lead response that arrives in 80ms feels instant. A response that takes 1.8 seconds from a cloud API creates a perceptible pause in conversational interfaces.
Three Mistakes to Avoid When Adopting SLMs
Mistake 1: Treating the SLM as a Drop-In Replacement Without Fine-Tuning
The biggest implementation failure is downloading Llama 3.1 8B, pointing it at your existing GPT-4 prompts, and expecting identical results. SLMs respond to instruction framing differently. They need shorter, more precise prompts. They benefit enormously from 3–5 concrete examples in the prompt (few-shot learning). And for high-accuracy tasks, even a small fine-tuning run on your business data produces results that a zero-shot prompting approach cannot match. Invest the 2–3 days it takes to tune the model properly before judging its capability.
Mistake 2: Starting With Your Most Complex Use Case
Complex, multi-step reasoning tasks — financial analysis, legal interpretation, strategic recommendations — are where the gap between SLMs and large models is most pronounced. Starting there and getting poor results leads teams to dismiss SLMs entirely. Start with your highest-volume, simplest tasks: ticket routing, FAQ response, data extraction from structured documents. Prove ROI there, then systematically assess which higher-complexity tasks are worth the SLM treatment. Many will surprise you with their performance.
Mistake 3: Ignoring the Integration Layer
An SLM that sits as a standalone tool is half an automation. The value multiplies when it is wired into your business workflows — your CRM, your helpdesk, your email automation system, your WhatsApp Business flows. Use an integration platform like Make or n8n to connect your SLM to the tools your team already uses. When a support ticket arrives, it should automatically flow through the SLM for classification, get the AI-generated draft attached, and land in the right agent's queue — all without manual steps. The SLM is the brain; the automation layer is the nervous system.
The SLM Shift: Cheaper AI Is Also Better AI for Most SMB Tasks
The narrative that "bigger model equals better results" was always a simplification. For broad creative and reasoning tasks, large cloud models remain the right choice. But for the structured, repeatable, high-volume AI work that generates most of the commercial value in SMB operations — classification, extraction, FAQ response, draft generation — small language models in 2026 are simply a better commercial decision. Ninety percent lower cost. Sub-100ms latency. Full data privacy. Zero vendor dependency. That combination is hard to argue against.
The SLM ecosystem has matured faster than most observers expected. Models like Phi-4 and Llama 3.1 are not compromises — they are engineering achievements that have shifted what "small" means in AI. More to the point, they are available right now, under commercial licences, on hardware your business can afford to operate.
The strategic question for 2026 is not whether to evaluate SLMs — it is which use cases to migrate first and how quickly you can extract the cost savings and privacy benefits. Use the AI Business Twin for a free, personalised analysis of which AI tasks in your business are best candidates for SLM migration.
Frequently Asked Questions
What is a small language model and how does it differ from a large one?
A small language model (SLM) is an AI model with between 1 billion and 14 billion parameters, compared to large language models like GPT-4 which have over 100 billion parameters. SLMs are designed to be efficient — they run on standard server hardware or even a business laptop, cost far less per token to operate, and can be deployed on-premise so your data never leaves your building. The trade-off is that SLMs are typically fine-tuned for specific tasks rather than being general-purpose assistants, which actually makes them more accurate and reliable for focused business applications like document classification, FAQ answering, or data extraction.
Which small language models are best for business use in 2026?
The leading SLMs for business in 2026 are Microsoft Phi-4 (14B parameters, exceptional reasoning for its size), Meta Llama 3.1 (8B and 70B variants, permissive commercial licence), Google Gemma 2 (9B, optimised for instruction-following), Mistral 7B (fast, low hardware requirements), and Qwen 2.5 (7B to 72B, strong at multilingual tasks). The right choice depends on your use case: Phi-4 for analytical tasks, Llama 3 for customer-facing text generation, Gemma 2 for following structured instructions, and Mistral for raw throughput on a budget.
Can a small language model replace ChatGPT for my business?
For most narrow business tasks — answering customer questions from a FAQ, classifying support tickets, extracting data from invoices, drafting templated emails — a well-tuned SLM matches or exceeds GPT-4's accuracy at a fraction of the cost. Where large models still have an edge is in complex multi-step reasoning, creative writing, and tasks that require broad world knowledge. The smart approach is to use SLMs for your high-volume, repeatable tasks and reserve large cloud models only for the small percentage of queries that genuinely need them.
What hardware do I need to run a small language model?
A 7B to 8B parameter model runs comfortably on a single consumer GPU with 16 GB VRAM, such as an NVIDIA RTX 4070 or better, or on a Mac with an M2 chip and 16 GB unified memory. For a 14B model like Phi-4 you want 24 GB VRAM or an M3 Max Mac. Most SMBs run SLMs on a single dedicated server or a cloud instance — a $0.50/hour A10G GPU instance on AWS or Google Cloud handles dozens of concurrent queries. You do not need a data centre. A well-specced business workstation is often sufficient.
Is it safe to use a small language model with my business data?
On-premise SLM deployment is one of the most secure AI architectures available to SMBs. Your data never leaves your server, there is no API call to a third-party cloud, and you have full control over access, logging, and retention. This is particularly important for businesses in healthcare, legal, and finance where client confidentiality rules may restrict sending data to third-party AI providers. Compare this to using GPT-4 via API where every prompt is transmitted to OpenAI's servers — SLMs eliminate that vector entirely.
How long does it take to deploy a small language model for a business use case?
A basic SLM deployment for a specific task — such as a customer FAQ chatbot or document classifier — takes one to three weeks from start to production with the right implementation partner. The steps are: selecting and downloading the base model, fine-tuning or prompt-engineering on your business data, setting up the serving infrastructure, and integrating with your existing tools via API. You do not need to train from scratch. Fine-tuning an existing SLM on your specific data typically requires only a few hundred to a few thousand labelled examples and takes hours on a single GPU.